Daily Trend [10-27]
【1】Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
【URL】http://arxiv.org/abs/2310.15110
【Time】2023-10-23
一、研究领域
Single-image-to-3D
二、研究动机
提升单视图3D生成的多视角一致性(同时利用pretrained stable diffusion的能力)和image conditioning;zero-shot.
三、方法与技术
(1)多视角联合分布建模:不是单纯地使用绝对视角,而是使用固定的绝对仰角和相对方位角作为新视图以消除 orientation ambiguity
(2)Noise Schedule:将 scaled-linear schedule 改为 linear schedule for noise. 因为前者会限制多视图的全局一致性(经验性观察)
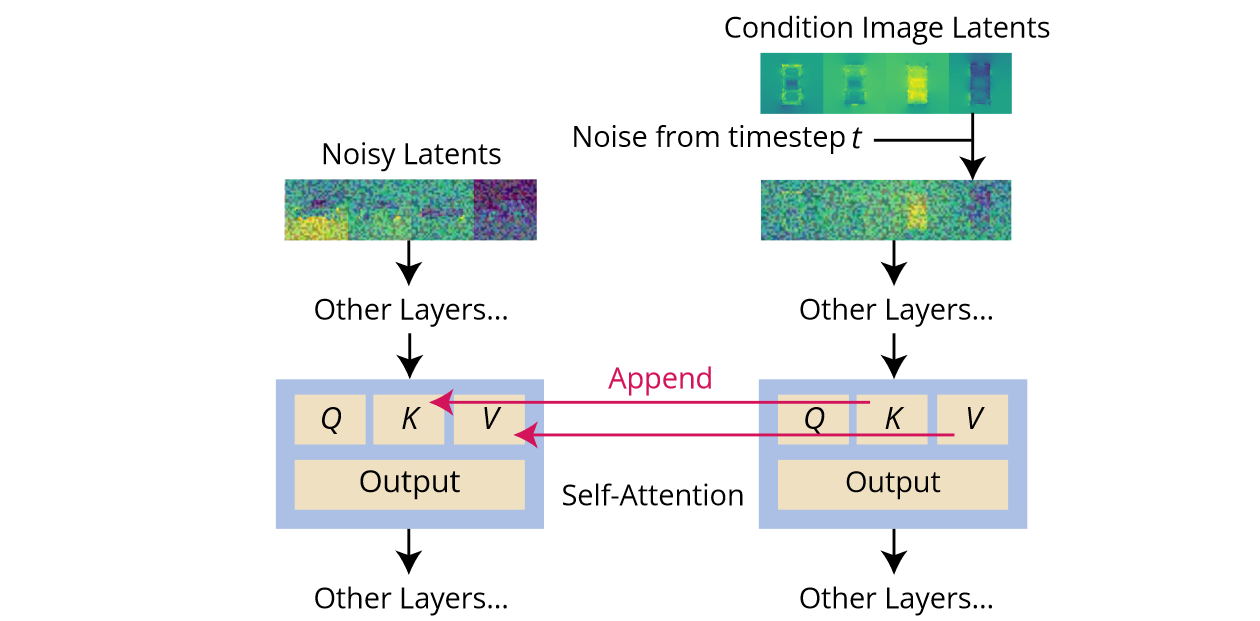
(3)Local Condition: Scaled Reference Attention:在reference image上运行扩散模型,将它在运行过程中的self-attention的key和value都加到目标的扩散模型上(不需要微调)
(4)Global Condition: FlexDiffuse:将原始的stable diffusion的text condition换成了image condition,原理是CLIP在image和text域上的对齐,具体其实就是把image embedding乘了一组可学习的参数丢进去一起训,方法和FlexDiffuse类似
四、总结
看下来感觉是很神秘的engineering work
http://y-ichen.github.io/2023/10/27/2023-10-27%20[Daily%20Trend]%20f6fed0095a76434aadd7ae24f0d51e09/
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.